Interpreter Design Pattern - An Introduction
A "Mostly" Gentle Introduction to Interpreter

Introduction
The Interpreter Design Pattern is the next of the Composable Design Patterns series.
Interpreter sits not only at the pinnacle of the Composable Design Patterns, but I think it resides at the top of the Gang of Four (GoF) design patterns sharing the position with the Visitor Design Pattern.
Interpreter is the fulfillment of customized-rule/policy-based behaviors, which I mentioned in Composable Design Patterns – Basic Concepts/Use Cases for Composability Design Patterns. Interpreter has the potential to support customer and user self-service features and behaviors. Customer/User self-service is a double-edged sword, which I’ll discuss in a bit more detail in a subsequent blog, Interpreter Design Pattern – Domain-Specific Languages - Tradeoffs.
Interpreter is one of the most powerful and elegant of the design patterns. Interpreter is the extension of Composite with the addition of context. Composite is syntax. Interpreter adds semantics to that syntax.
But Interpreter doesn’t receive the attention it deserves.
It’s one of the nine GoF design patterns relegated to Appendix A. Leftover Patterns in Head First Design Patterns. This Appendix is a round up of patterns that the book didn’t describe in detail. Each of these nine patterns gets about two pages of attention which is woefully insufficient for anything beyond an overview.
Refactoring Guru excluded Interpreter from its pattern catalog. Interpreter is the only GoF pattern missing.
Sourcemaking includes Interpreter, but there’s an error of omission in one of their diagrams. Their structure diagram is missing the relationship line that’s the equivalent of the Composite class reference back up to the Component interface.
Background
Ironically, I think the GoF authors are mostly responsible for this lack of attention. While their 14-page description of Interpreter is not technically wrong, it just feels incomplete. I suspect that many readers don’t understand what the GoF were trying to convey. Their class diagram is correct, but it only hints at the potential of the pattern. It’s like a biology textbook presenting stem cells without explaining how stem cells can become nerve cells, muscle cells, blood cells, etc.
The GoF assume their readers have knowledge of programming language design, grammars, scanners, parsers, etc. These may have been reasonable assumptions in 1995 at the time of publication, but today’s software developers might not have the same foundations. The authors were academics, and these are topics that most computer science students learned to some degree. Self-taught developers, bootcamp developers and developers who have degrees in other fields, may not have the background to follow the GoF’s description.
The implementation examples feel a bit dated, especially the Smalltalk implementation example.
I stumbled upon a blog years ago written by a manager at Amazon, that included statements along these lines:
I thought the Gang of Four’s Design Pattern book was fantastic. I understood everything, except pages 243-257. …
I grabbed my copy of the GoF book off the shelf and turn to 243. It was Interpreter.
The blog continued:
… I eventually figured it out. From then on, I’d ask all interviewees if they could explain Interpreter to me. If they could do so sufficiently, then I’d offer them the job on the spot.
Interpreter was the final design pattern I understood. That was 7 years after I had started to learn the design patterns. I had tried, really tried, to understand it earlier. I didn’t understand the GoF’s description. I couldn’t find any alternative online descriptions that clicked with me. I sort of stumbled into my understanding of it by accident. Then once I understood it, it was an epiphany. I understood what the GoF were trying to say, well mostly. Interpreter is so elegant. Why had I not seen its elegance before?
Shoring up the Gang of Four
I will try to fill in some of the missing gaps from the GoF’s Interpreter presentation. Don’t worry, you won’t need access to their 14 pages. I’ll copy snippets from the book when I want to highlight sections that I’m addressing.
This is going to be a journey of multiple blogs entries. By the time I have finished, I hope I have filled enough gaps so that most can understand Interpreter and appreciate its elegance as well.
I think Source Making Interpreter distilled the elegance quite elegantly:
Map a domain to a language, the language to a grammar, and the grammar to a hierarchical object-oriented design.
Even with this elegant description, a few more specifics would be useful.
Here’s the rest of the Interpreter story over seven blog posts:
- Domain-Specific Languages
- Programming Language Grammars
- Grammars to Design
- Design to Implementation
- Scanners and Parsers, Theory and Practice
- Scanners and Parsers, Implementation: Rational Expression Implementation Example Completed
- Interpreter Design Pattern – Production Example: My Experience Using Interpreter on a Work Project
Specification is Interpreter
While I think I will need additional blogs to describe Interpreter sufficiently, I can provide a quick overview here.
Interpreter can sound intimidating with grammars, parsers, etc. But we’ve already encountered an Interpreter example in this blog series. Specification is a specialized and limited scoped Interpreter. If someone can understand the nuts-and-bolts of Specification, then Interpreter isn’t much of a leap beyond that. I featured Specification in the two previous blogs (Specification and Smart Playlist Use Case) because it’s a steppingstone toward understanding Interpreter as a whole.
Coincidentally, the GoF used a similar problem, a Boolean expression evaluator, for their C++ Interpreter example. Specification is a Boolean evaluator as well. The main difference between the GoF example and Specification is the leaf nodes. Leaf nodes in the GoF example are either Boolean variables or true/false Boolean constants. With Specification, the leaf nodes are Boolean values based upon the satisfiability of the field attributes within a Context object. In the case of the Smart Playlist Specification, the leaf node Boolean values derive from a Track’s Genre, Rating, Artist, and other attributes.
The GoF don’t show all the steps from grammar to implementation in their C++ example. I’m going to fill in a few of the gaps with Specification as the context as a short primer. I’ll present more details in the subsequent blog entries.
Domain-Specific Language Primer
Specification is a Domain-Specific Language (DSL). A DSL is a small language that’s designed for a specific domain. In the Smart Playlist Use Case, it’s a domain that allows the user to organize Smart Playlists based upon a set of user defined rules that dynamically organize tracks in those playlists based upon their attribute values.
A DSL is a specialist. It solves problems in its domain very well. But venture beyond its domain, and it loses its power. A general-purpose language, such as C++, Java and Python, can accommodate any domain, but not without additional domain support or infrastructure. One could argue that a well designed general-purpose language implementation should eventually become domain specific through consistent nomenclatures with its class, method, parameter and field attribute names. But unless a ubiquitous language is enforced, we often don’t achieve this.
A DSL allows you to solve a problem succinctly if the problem is within the domain. A general-purpose language allows you to solve any problem, but it may take more time to establish domain foundations before achieving a solution.

The fox knows many things, but the hedgehog knows one big thing. — Archilochus, Greek Lyric Poet
A Domain-Specific Language is a Hedgehog.
A General-Purpose Language is a Fox.
Programming Language Grammar Primer

To the best of my knowledge all programming languages are defined via grammars, including DSLs. A grammar is a set of rules that documents the syntax and structure of a programming language:
- All programs in a programming language can trace their structure back to grammar rules.
- Each program projects a unique parse tree consistent with its grammar rules. This is like sentence diagramming.
- The tree leaf nodes correspond to the language elements in the program itself, such as keywords, identifiers, symbols, etc.
- The tree non-terminal nodes indicate the relationship among the leaf nodes and other non-terminal nodes. That is, they support the organization structure.
- Behaviors are added to the organization structures. This is technically beyond grammar definition, but it’s the last step achieving behavior from programming languages defined via a grammar.
The same grammar rules that support “Hello World!” are the same ones that support the most sophisticated software systems ever created. The only difference is in the size and complexity of the program itself and the unique parse tree that’s projected from the program.
DSLs tend to have smaller grammars than general-purpose programming languages. They may consist of only a handful of rules. A surprisingly small Interpreter implementation can accommodate the elements of a DSL. This makes Interpreter an ideal implementation for a DSL as we’ll eventually see.
Most DSL programs tend to be small, but there’s no restriction on the size of the program. Staying with the Specification example, it could be a specification with one statement, and therefore one object in the tree. Or it could be a specification of hundreds of statements and therefore hundreds of objects in the tree.
Grammars generally have three basic rule types:
- OR rule, which lists the grammar rules that are more specific versions of the general rule.
- AND rule, which defines the language elements and grammar rules that comprise this rule.
- DEFINITION rule, which is a rule that’s not defined in terms of other rules.
Here’s a quick example of some grammar rule syntax:
RuleX ::= RuleA | RuleB // i.e., RuleX can become RuleA OR RuleB
RuleA ::= "A" "(" RuleX ")" // i.e, RuleA is comprised of "A" AND "(" AND RuleX AND ")".
RuleB ::= "B" // i.e., DEFINITION
The OR operation is denoted by |. The AND operation is assumed, much like multiplication is assumed in algebra when not specified. We assume that mass and acceleration are being multiplied in F = ma. The same applies to grammar rules. Assume AND when not provided.
NOTE: Grammar rules originate from automata theory. Their use in defining programming languages is a practical application.
Smart Playlist Specification
We’re going to start with the Specification Smart Playlist Use Case and specifically the smart playlist that specifies Five Star ratings for Alternative, Rock and New Wave tracks as long as they are not The Rolling Stones or U2.
iTunes provides a GUI for the user. Interpreters tend to be text based. If iTunes had instead provided a text-based version to specify smart playlists, then the above GUI representation might look more like this text specification, which mirrors the GUI image above, but with text rather than graphics:
fiveStarAltRock = all(
any(
genre(Alternative),
genre(Rock),
genre(New Wave)
),
all(
rating(5),
all(
artist(not(“The Rolling Stones”)),
artist(not(“U2”))
)
)
)
Smart Playlist Attributes
Before jumping into the grammar, let’s jot down a few observations:
- Genre is a Specification.
- Rating is a Specification.
- Artist is a Specification.
- All is a Specification.
- All has a collection of Specifications.
- Any is a Specification.
- Any has a collection of Specifications.
- Not is a Specification.
- Not has a single Specification.
Notice that all of these observations are described in terms of IS-A or HAS-A. IS-A will have a relationship with OR. HAS-A will have a relationship with AND.
Smart Playlist Grammar
Given this brief example and the grammar notation above, we can define a Specification grammar as:
Specification ::= Genre | Rating | Artist | All | Any | Not
Genre ::= "genre" "(" genreType ")"
Rating ::= "rating" "(" ratingValue ")"
Artist ::= "genre" "(" artistName ")"
All ::= "all" "(" SpecificationList ")"
Any ::= "any" "(" SpecificationList ")"
Not ::= "not" "(" Specification ")"
SpecificationList ::= Specification ["," Specification]* // NOTE: Star indicates any number of repetitions, including zero.
The Not and SpecificationList rules include Specification in their definition. This means that the grammar is indirectly recursive. This is what allows all, any and not constructs to be nested. The grammar supports a tree structure that’s as deep and wide as needed.
Grammar to Design
The class design emerges from the grammar, especially since IS-A is associated with inheritance and HAS-A is associated with composition. Interfaces tend to map to OR grammar rules, and concrete classes tend to map to AND grammar rules. Abstract classes are not part of the grammars and tend to emerge during design refactoring. Compare the grammar above with the class design. Hopefully the major relationships in the grammar and the design are obvious:
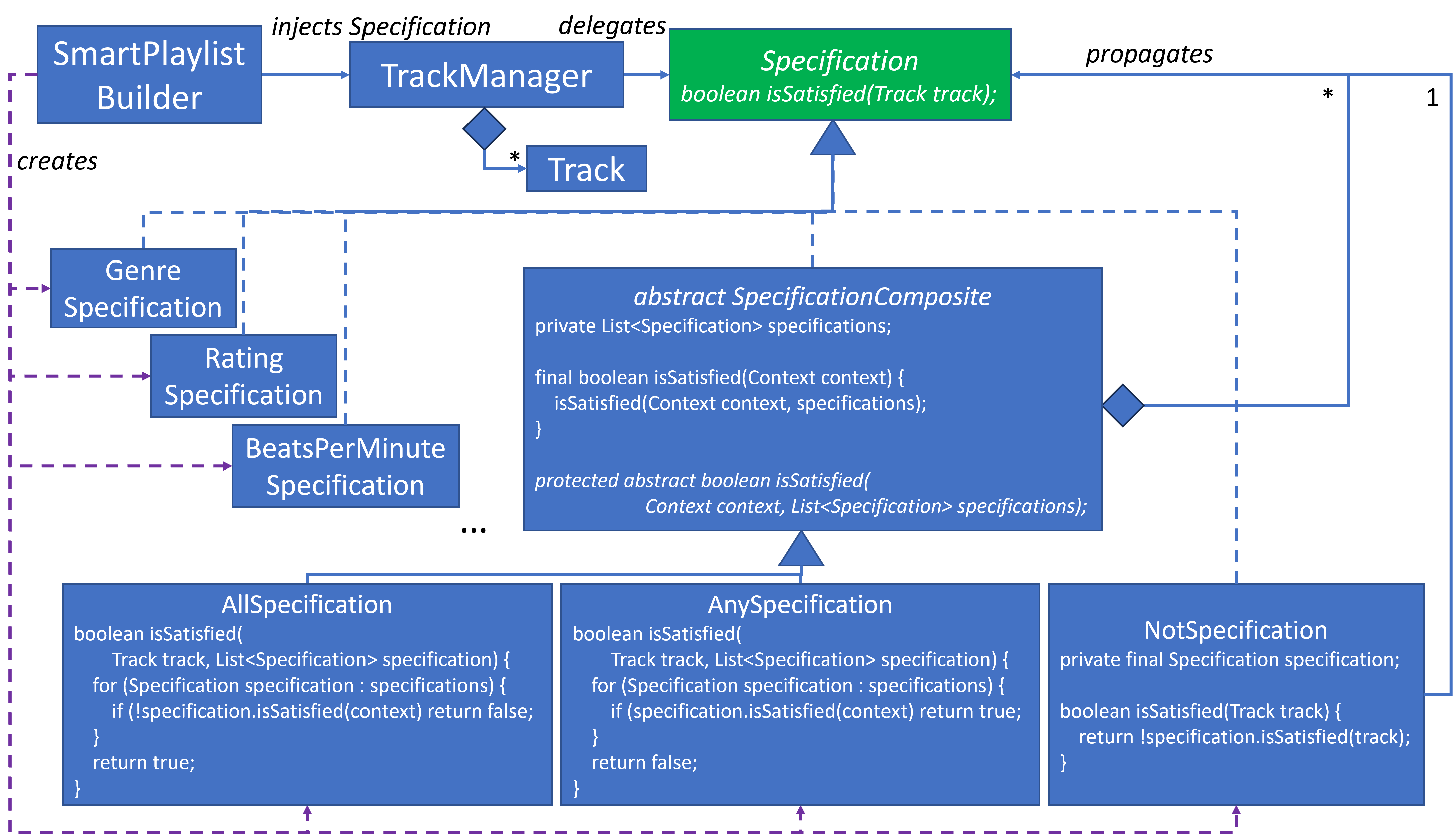
Scanner and Parser
We still need to convert the fiveStarAltRock text definition above into the following object tree (NOTE: The names, such as genres, constraints, etc. won’t be in tree. This is a copy of the tree from the previous blog, which composed the tree with hardcoding and intermediate Composite variables.):
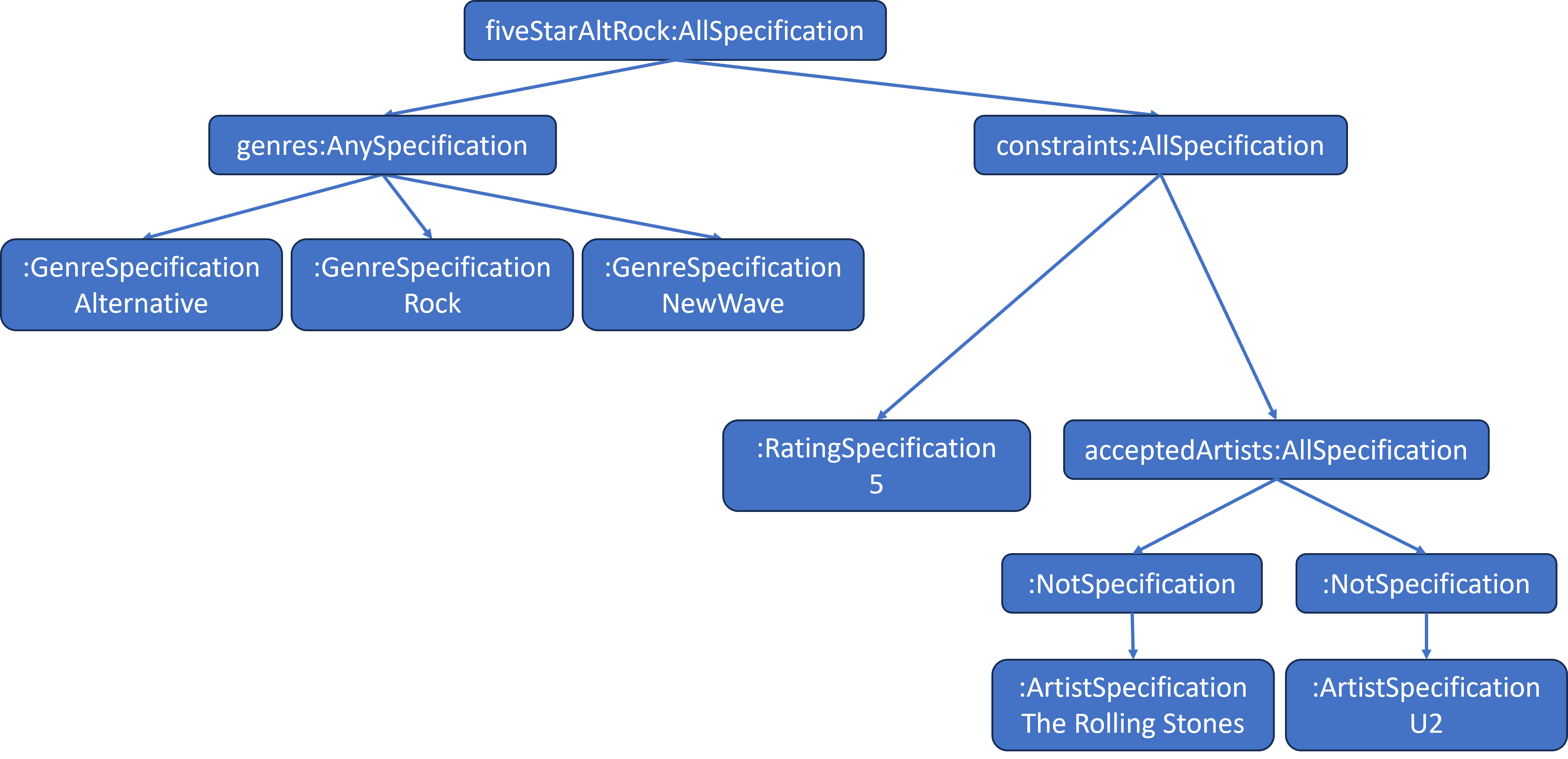
This will be done by:
- The scanner, which extracts individual tokens from the text definition.
- The parser, which creates objects based upon the tokens and assembles them. Since the grammar is recursive, the parser will be recursive as well.
There are whole books and college courses about scanners and parsers. I can only scratch their surface here or in subsequent blogs.
The scanner and parser together are a type of Configurer. Previous Configurer examples have mostly been hardcoded. Scanners and parsers are different. The result is still a set objects configured in a data structure — in this case a parse tree. The difference is that the object tree will be based upon a program consistent with the grammar. A program can be thought of as a blueprint for the object tree. The scanner and parser will construct the object tree based upon that blueprint. Their behavior is close to the Builder Design Pattern.
Once the object tree, as shown above, has been constructed, then Tracks can be passed to it to determine their satisfiability based upon a Track’s attributes and the configuration of the Specifications in the tree.
Summary
Interpreter is a great approach for implementing a Domain-Specific Language. Interpreter is part of the algorithmic process from Domain-Specific Language to Grammar to Design to Implementation.
Also see: Interpreter Design Pattern AI Notebook.
References
There are additional online resources with diagrams and implementations in different programming languages. Here are some free resources:
- Wikipedia Interpreter Design Pattern
- Source Making Interpreter Design Pattern
- Baeldung Interpreter Design Pattern in Java
- OODesign Interpreter Design Pattern
- Learn CS Design Interpreter Design Pattern
- DoFactory Interpreter Design Pattern
- Reactive Programming Interpreter Design Pattern
- and for more, Google: Interpreter Design Pattern
Here are some resources that can be purchased or are included in a subscription service:
- Gang of Four Composite Design Pattern, page 243 (O’Reilly and Amazon)
- Head First Design Patterns, Appendix A: Leftover Patterns, Interpreter (O’Reilly and Amazon)